
How domain-specific AI and curated benchmarks are shaping the future of legal claim analysis
Ankan Roy
DocLens.ai
Background
Large Language Models (LLMs) are showing real promise in analyzing complex legal and insurance documents. However, ensuring factual accuracy is still a major challenge, especially in high-stakes areas like property and casualty (P&C) insurance claims.
In this study, we introduce benchmark datasets and an evaluation framework to test the factual and semantic accuracy of AI-generated summaries in liability claim analysis which involves analyzing both the medical and the legal aspects of a claim. The datasets consist of manually curated question-answer pairs from publicly available bodily injury insurance claim files. This allows comparison between our proprietary domain-specific model, ClaimLensTM, and an off-the-shelf LLM, Claude 3.5 Sonnet, V1 with prompts.
Using precision and recall metrics alongside semantic similarity scoring with legal-domain prompts, our results show that ClaimLens outperforms state-of-the-art generic Large Language Model, particularly on subjective and multi-document questions. We also highlight rare edge cases that reveal ongoing challenges in legal document comprehension. These findings emphasize the need for domain-specific evaluation criteria and carefully curated ground truth for building reliable, legally grounded LLM systems.
Why This Matters
LLMs have shown strong potential in legal, financial, and medical document analysis. In the legal domain, they are used for judgment prediction, drafting legal text, and document review, helping improve efficiency and access to justice (Sun, 2023).
But legal documents are complicated. They are long, often unstructured, and full of nested clauses and cross-references. This makes it difficult for LLMs to process them accurately. Even top models like GPT-4 can lose context if the document is too long, like trying to read a novel one paragraph at a time and missing the plot (Davenport, 2025).
This is where DocLens.ai comes in.
How DocLens.ai Helps
DocLens.ai transforms how P&C insurance claims are analyzed. Its platform, ClaimLensTM, is an AI-powered framework that helps legal and insurance professionals review complex claim files efficiently.
Claim files can run into hundreds of pages of medical records, legal filings, and correspondence. ClaimLens digests this information and produces structured outputs, such as:

A chat interface allows users to query the claim file in natural language. The AI responds with grounded answers and cites the relevant documents, helping users quickly verify facts or insights. Think of ClaimLensTM as an assistant that pieces together a complex puzzle, turning hundreds of pages into actionable summaries.
Purpose of This Study
To assess how reliable ClaimLens is, we need robust evaluation benchmarks and datasets. This study outlines the creation of a ground truth dataset and evaluation framework.
The dataset contains manually curated question-answer pairs from multiple real-world claims, with precision and recall measured for both ClaimLens and an off-the-shelf LLM baseline.
How We Built the Benchmark
Dataset Structure
We created four datasets based on public court records: James Spangler, James Barwick, Barbara, and Glenford Hardy. Each dataset contains questions about the claim and answers from three sources:
- ClaimLens (domain-specific LLM)
- Claude 3.5 Sonnet (general-purpose LLM)
- Ground Truth (manual reference)
Answers are evaluated using precision, recall, and semantic similarity, stored in JSON format. This lets us analyze factual accuracy and semantic alignment across legal documents.
Types of Questions
Each dataset includes nine evaluation questions, covering objective facts and subjective summaries.
- Objective questions are simple, like claimant name or age.
- Subjective questions require synthesis across multiple documents, like describing the incident or summarizing injuries.
The questions are grouped into four categories:
- Claim Summary – Core case details.
- Medical Summary – Clinical aspects of the claim.
- Risk Report – Legal and contextual risk factors.
- Demand Summary – Financial dimensions of the claim.
This framework balances fact retrieval with interpretive summarization, reflecting the real-world challenge of analyzing complex claims.
Using Off-the-Shelf LLMs
For comparison, we generated answers using Claude 3.5 Sonnet. This model is fast and performs well on context-sensitive, multi-step reasoning tasks (Anthropic, 2024).
Documents were parsed from legal PDFs using PyPDF. To stay within Claude’s input limits, we split longer documents into ~1000-character chunks until a 150,000-token ceiling was reached. This ensured Claude could access key content fairly, without replicating ClaimLens’s proprietary summarization logic.
Why Domain-Specific Benchmarks Are Needed
Legal AI presents unique challenges. General-purpose LLMs often fail to handle nuanced legal reasoning. Existing benchmarks like LEGALBENCH focus on specific jurisdictions or static datasets, limiting their usefulness (Cao et al., 2025; Guha et al., 2025).
We created a custom benchmarking framework for legal claims, considering exact entities, financial figures, and injury assessment. This allows consistent cross-model comparisons and supports fine-tuning for domain-specific tasks.
Evaluating Model Performance
We use two complementary methods:
- Precision and Recall – Measure factual correctness. Errors are weighted differently depending on question type. For example, in Claim Summaries, incorrect names are penalized, while minor wording differences are tolerated in Risk Reports.
- Semantic Similarity – Scores alignment with ground truth on a scale of 1 to 5, capturing interpretive fidelity (Ragas, 2025).
Together, these methods measure both strict factual accuracy and broader semantic alignment, reflecting how legal professionals evaluate claims.
Accuracy
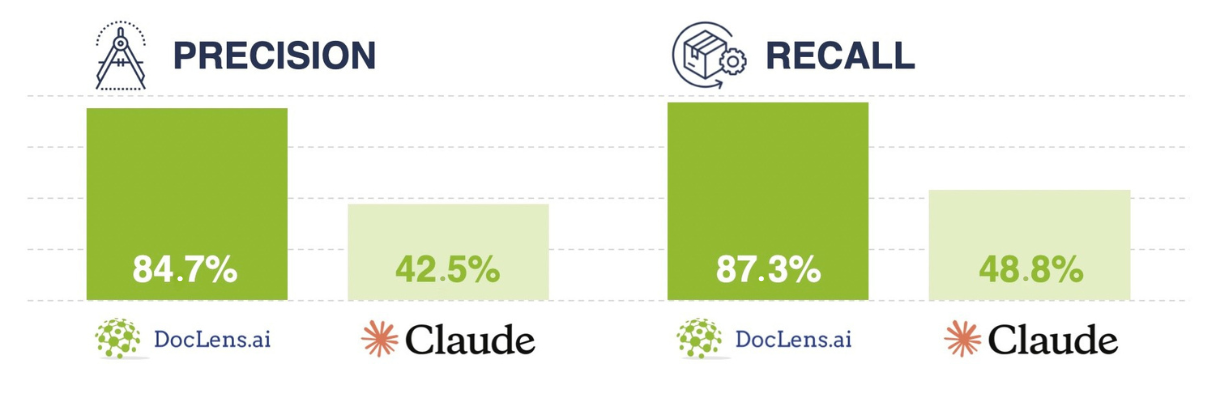
What We Found
Using domain-sensitive evaluation, ClaimLens outperformed Claude across the board:
- Precision: 84.7% vs 42.5%
- Recall: 87.3% vs 48.8%
- Semantic similarity: 4.0/5 vs 2.72/5
Objective questions were easy for both models. Subjective questions revealed the gap, with Claude producing incomplete or general answers. ClaimLens provided detailed, accurate summaries by leveraging full documents and domain logic.
Rare misattributions occurred, like in the James Barwick case, where ClaimLens pulled information from comparator cases. This shows the importance of combining automated metrics with manual inspection to catch edge cases.
The Road Ahead
The evaluation framework can be applied to any legal benchmarking dataset with clearly defined question types.
Future work includes:
- Running the test on a periodic basis on an expanded set of curated data and an expanded set of questions
- Covering broader legal fact patterns, jurisdictions, and document types.
- Testing newer LLMs such as Claude 4 Opus to track advances and refine domain-adapted models like ClaimLens.
This will make the framework applicable beyond insurance claims to other areas of law, building a legally grounded benchmarking tool.
Comments